The architecture of a large language model (LLM) is influenced by several factors, including the specific goals of the model, the computational resources available, and the kind of language processing tasks it’s designed to perform. Here’s a breakdown of the key components that make up a typical LLM architecture:
Transformer Networks: At the core of most contemporary LLMs lies the Transformer architecture. This neural network departs from traditional recurrent neural networks (RNNs) and excels at understanding long-range dependencies within sequences, making it particularly well-suited for language processing tasks. Transformers consist of two sub-components:
Encoder: This section processes the input text, breaking it down into a series of encoded representations, capturing the relationships between words.
Decoder: Here, the model leverages the encoded information from the encoder to generate the output text, one word at a time.
Self-Attention Mechanism: This ingenious mechanism within the Transformer allows the model to focus on the most relevant parts of the input sequence for a given word or phrase. It attends to different parts of the input text differentially, depending on their importance to the prediction at hand. This capability is crucial for LLMs to grasp the nuances of language and context.
Input Embeddings and Output Decoding
Input Embedding: Before feeding text data into the LLM, word embedding transforms it into numerical representations. This process converts words into vectors, capturing their semantic similarities and relationships.
Output Decoding: Once the LLM has processed the encoded input, it translates the internal representation back into human-readable text through decoding
Model Size and Parameter Count: The number of parameters (weights and biases) within an LLM significantly impacts its capabilities. Large-scale LLMs often have billions, or even trillions, of parameters, allowing them to learn complex patterns and relationships within language data. However, this also necessitates substantial computational resources for training and running the model.

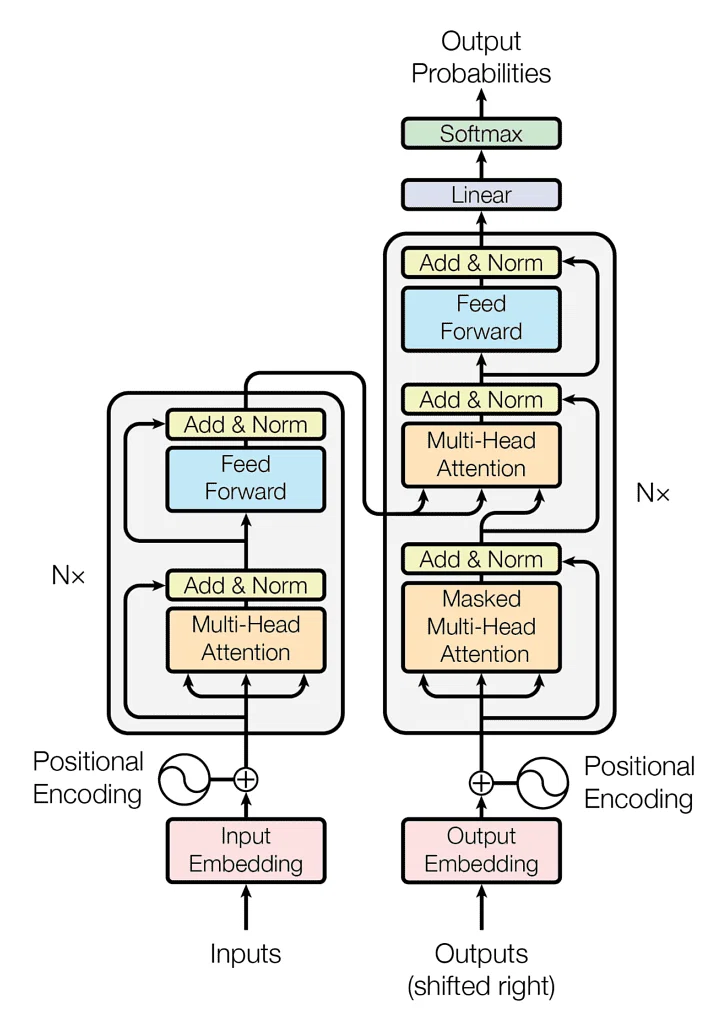 In the encoder-decoder architecture used in translation, the encoder can analyze the entire source sentence simultaneously, while the decoder attends to previously translated words and the complete source sentence to generate the target language. This allows the model to consider word order and context across the entire sentence for accurate translation.
In the encoder-decoder architecture used in translation, the encoder can analyze the entire source sentence simultaneously, while the decoder attends to previously translated words and the complete source sentence to generate the target language. This allows the model to consider word order and context across the entire sentence for accurate translation. 


